[2022.11월 OCR 개발 관련 survey]
<Scene Text Detection and Recognition: The Deep Learning Era>
본 논문은 정지 장면 이미지에서 deep learning 기반 text detection과 text recognition을 연구, 각 model들을 비교 분석한 논문이다. 최근에는 OCR을 deep learning 기반으로 개발하는데, detection 부분과 recognition 부분으로 나뉘어져 있다.
내가 맡은 개발 파트는 text detectection이기 때문에 이 부분에 집중하여 survey를 진행했고 정리했다.
https://arxiv.org/pdf/1811.04256v5.pdf
논문에 기재된 OCR 방법은 크게 deep learning 기반의 유무로 나뉜다.
Method before the Deep Learning Era- Methodology in the Deep Learning Era
Methodology in the Deep Learning Era의 detection 시도에는 3단계가 존재한다.
- Early Attemps to Utilize Deep Learing; 딥러닝을 활용하려는 초기 시도
- Methods Inspired by Object Detection; OD에서 영감을 얻은 방법
- Methods Based on Sub-Text Components; 하위 텍스트 구성요소 기반 방법
1. Early Attemps to Utilize Deep Learning; 딥러닝을 활용하려는 초기 시도
딥러닝을 활용하려는 초기에는 multi pipeline을 갖추고는 있지만, 느리고 복잡하다는 단점이 존재한다.
| Text Detection의 1단계 | |
| Huang et al. (2014) | CNN이 local image patch를 텍스트인지 비텍스트인지 분류하는 데에 사용되고, 이후 positive patch가 text line으로 합쳐진다. |
| Tian et al. (2015) | CNN을 사용하여 문자를 감지하고 문자 그룹화 과정을 min-cost flow 문제로 본다. |
| Yao et al. (2016) | CNN을 사용하여 input image의 각 pixel이 (1) 문자에 속하는지, (2) 텍스트 영역에 있는지, (3) pixel 주변의 텍스트 방향 쪽에 있는지 예측한다. |
| Zhang et al. (2016) | 텍스트 라인 영역을 나타내는 segmentation map을 먼저 예측하고, 각 라인에 대해 문자 후보를 추출하여 각 라인의 scale과 oreientation에 대한 정보를 표시한다. 이후 minimum bounding box가 최종 텍스트 라인 후보로 추출된다. |
| He et al. (2017a) | 텍스트 블록이 추출된 후, 텍스트 블록에만 초점을 맞춰 Text Center Line(TCL)을 추출한다. 각 텍스트 줄은 하나의 텍스트 instance를 뜻한다. 이후 sementic segmentation 모델에서 각 pixel을 주어진 TCL과 동일한 instance인지 아닌지 분류한다. |
2. Method Inspired by Object Detection: OD에서 영감을 얻은 방법
이후 연구자들은 Object Detection algorithm에서 영감을 얻어 general detection의 영역 제안 및 bounding box 회귀 모듈을 text instance로 맞춰 설계하기 시작했다.
주로 convolutional layer를 통해 input image를 feature map으로 인코딩한다. 그런 다음 각 feature map의 공간 위치가 input image 영역에 대응하고, 그 각 공간 위치에서 text instance를 예측하기 위해 feature map이 분류기에 입력된다.
이러한 방식은 pipeline의 end-to-end 훈련으로 더 쉽고 빠르게 훈련 가능하게 한다.
| Text Detection의 2단계 | |
| TextBoxes | 기본 상자를 다양한 비율의 사각형 형로 만들어 text의 다양한 방향과 비율에 맞게 SSD를 조정한다. |
| EAST | U자형 설계를 채택하여 서로 다른 level의 feature들을 통합하여 anchor 기반 detection을 단순화한다. input image를 다른 여러 layer(SSD)가 아닌 하나의 multi-channel feature map으로 인코딩된다. (텍스트/비텍스트, 직사각형의 방향과 크기, 4각형의 정점 좌표 예측) --> 매우 단순화된 pipeline과 실시간 추론으로 효율성 상승 |
| R-CNN | R-CNN의 2단계 OD를 적용하여 ROI에서 얻은 feature를 기반으로 localization을 수정한다. |
| Me et al. (2017) | 회전 영역 제안 네트워크는 축에 정렬된 직사각형 대신 임의의 방향을 가지고 있는 text에 맞추기 위해 회전 영역 제안을 생성한다. |
| FEN, Zhang et al. (2018) |
크기가 다른 ROI 풀의 가중 합계가 사용되어 최종 예측은 4개의 서로 다른 ROI 풀링에 대한 textness 점수를 활용하여 이루어진다. |
| Zhang et al. (2019) | ROI 및 localization branch를 재귀적으로 수행하여 text instance 예측 위치를 수정한다. |
| Wang et al. (2018) | ITN(Instance Transformation Network)를 사용하여 text instance를 수정할 것을 제안한다. |
| Liu et al. (2017) | 불규칙한 모양의 text를 다루기 위해 14개의 정점을 가진 bounding 다각형을 제안하고, Bi-LSTM layer를 사용하여 예측된 정점의 좌표를 미세 조정한다. |
| Wang et al. (2019b) | RPN 기반 2단계 OD에 의해 인코딩된 feature를 읽고 가변 길이를 가진 bounding polygon을 예측하기 위해 RNN을 사용한다. 이 방법은 후처리나 복잡한 중간 단계를 필요로 하지 않아 빠른 속도를 가진다. |
* RPN(Region Proposal Network): Faster R-CNN에서 활용되는 것으로, 다양한 사이즈의 이미지를 입력하여 object score와 object proposal을 구하고 sort한다. 이후 NMS(Non Maximum Suppression)와 merge를 수행하여 ROI를 출력한다. 기본적으로 regression과 classification을 통해 OD를 수행한다.
이 단계에서 detection pipeline의 단순화와 그에 따른 효율성 향상을 이루었지만 여전히 긴 text나 곡선 text에 대해서는 성능이 제한된다는 한계점이 존재한다.
3. Methods Based on Sub-Text Components; 하위 텍스트 구성요소 기반 방법
text detection과 일반적인 object detection의 주요한 차이점
text가 전체적으로 균질하며 일반 object detection과는 다른 지역성을 특징으로 한다. text의 동질성과 지역성으로 인해 text instance의 어떤 부분이라도 text의 속성을 가지고 있다고 간주할 수 있다.
새로운 text detection 방법의 등장
text의 동질성과 지역성이라는 특징은 하위 text 구성 요소를 예측하고 text instance로 조립하는 새로운 text detection 방법을 제시한다. 이 방법은 neural network를 사용하여 local 속성이나 segment들을 잘 예측하고, 이는 특성상 곡선, 긴 방향 text에 더 잘 적용된다. 이 방법에서 text instance를 재구성하기 위해 후처리는 사용되기는 하지만, 초기 다단계 방법에 비해 neural network에 더 많이 의존하고 pipeline 또한 짧다.
하위 텍스트 구성요소 기반 방법의 장단점
text instance의 모양과 가로 세로 비율보다 더 나은 flexibility와 generalization을 갖는다. 하지만 text instance로 그룹화하는 데 사용되는 모듈이나 후처리 단계가 noise에 취약할 수 있으며 플랫폼마다 효율성이 다를 수 있다는 단점이 존재한다.
| Text Detection의 3단계 | ||
| Pixel-level method |
> pixel-level 방법은 end-to-end FCN을 통해 원본 이미지의 각 pixel이 text instance에 속하는지의 여부를 나타내는 예측 맵을 생성하는 방법이다. > 이후 후처리를 통해 동일한 text instance에 속하는 pixel을 그룹화한다. > text instance를 서로 분리하는 것이 핵심이다. |
|
| Wu and Natarajan. (2017) | 경계 학습 방법으로, 경계가 text instance를 잘 분리할 수 있다고 가정하여 각 pixel을 text, border, background로 캐스팅한다. | |
| Wang et al. (2017) |
pixel들은 색상 일관성과 edge정보에 따라 클러스터링된다. 이렇게 클러스터링된 image segment들을 superpixel이라 하는데, text instance를 예측하는 데에 사용된다. |
|
| PixelLink, Deng et al. (2018) |
PixelLink는 인접 pixel 간의 link를 나타내기 위해 output channel을 추가하여 두 pixel이 동일한 text instance에 속하는지 예측하는 방법이다. | |
| Tian et al. (2019) |
서로 다른 text instance에 속하는 pixel 임베딩 벡터 간의 유클리드 거리는 최대화하고, 같은 text instance에 속하는 벡터는 최소화하여 인접 text을 더 잘 분리하는 loss를 추가한다. | |
| Wang et al. (2019a) |
서로 다른 수축 스케일로 text 영역을 예측하고, 다른 instance와 충돌할 때까지 text 영역을 라운드별로 확대한다. | |
| Component-level method |
> 대표적인 component-level 방법은 Connectionist Text Proposal Network(CTPN)이다. > CTPN 이란? CNN위에 RNN을 쌓아 일련의 text proposal에서 text line을 detect하는 모델로, 최초로 deep neural network를 이용해 scene text의 segment 예측 및 연결했다. 최종 feature map을 통해 3개의 출력 layer가 제공되는데, k를 anchor 상자 수로 두었을 때 2k개의 vertical coordinate와 2k개의 text/non-text에 대한 score, k개의 side-refinement layer이다. |
|
| SegLink, Shi et al. (2017a) |
segment 간의 다중 지향적 연결을 고려하여 CTPN을 확장한 방법이다. segment detection은 *SSD를 기반으로 하고, 각 default box는 text segment를 나타낸다. default box 사이의 link는 인접한 segment가 동일한 text instance에 속하는지의 여부를 나타낸다. |
|
| * SSD: 1-stage detector이지만, fc layer가 아닌 conv layer를 통해 속도를 향상시키고, conv layer에서 얻은 여러 scale의 feature map 6개를 예측에 사용하여 정확도를 높인 방법 |
||
| Zhang et al. (2020) |
GCN(Graph Convolutional Network)를 사용하여 segment 간의 연결을 예측하여 SegLink를 추가로 개선한다. | |
| Corner localization method, Lyu et al. (2018b) |
> 각 text instance의 네 모서리를 검출한다. > 각 text instance에는 네 개의 모서리만 존재하기 때문에 예측 결과와 상대 위치로 어떤 모서리들이 동일한 text instance로 그룹화될지 보여줄 수 있다. |
|
| TextSnake Long et al. (2018) |
> text가 text instance의 실행 방향에 일치하는 중심선(Text Center Line)을 따라 일련의 슬라이딩 원형 디스크로 표현될 수 있다. > 새로운 표현 방식이 등장함에 따라 새로운 모델 TextSnake이 등장했으며, TCL/비TCL, text region/non-text region, 반경, 방향을 예측하는 방법을 학습한다. > TCL pixel들과 text region pixel들의 교차로 최종적으로는 pixel-level TCL을 예측하여 추출하면 TCL 및 반지름을 사용하여 text line이 재구성된다. |
|
| Character -level, Baek et al. (2019b) |
> character center에 대한 segmentation map과 그들 사이의 link를 학습한다. > component와 link 모두 Gaussian heat map 형태로 예측된다. > 실제 데이터셋에 character-level label이 거의 없어서 약한 감독 과정이 필요하다. |
|
PixelLink, EAST, SegLink, CTPN 모델의 R(recall), P(precision), F(F-score)는 다음과 같다.
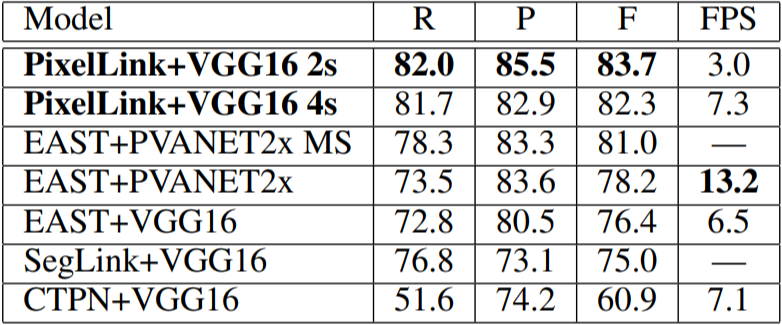
내가 개발하고자 하는 OCR은 Scene text가 아닌 일정한 크기와 위치에 text가 있는 문서를 target으로 하기 때문에 box의 크기와 모양이 Scene text에 비해서는 다양하지 않다. 개발 목표와 논문에 기재되어 있는 성능 지표를 고려했을 때 이 중에서 PixelLink 모델이 적합하다고 판단했다.
따라서 OCR detection model로 PixelLink 모델을 사용하고자 한다.
다음 단계는 PixelLink에 대한 학습을 진행할 예정이다.
'ㄴ 공부공부룸 > AI' 카테고리의 다른 글
| [위변조] CAT-Net (0) | 2023.01.13 |
|---|---|
| 하이퍼파라미터 튜닝 (0) | 2022.12.06 |
| [OCR] PixelLink (0) | 2022.12.06 |


